
Pop quiz: “Can you build a 99.99% service on top of 99.9% infra?” Counterintuitive spoiler: yes, you can. Canonical examples include highly-available RAID and Storage Area Networks built out of commodity hard drives. Historical thinking holds that the foundation must be more reliable than the systems built on top. In the inverted model, the system is more reliable than its dependencies. If you’re in the cloud, then you already rely on the inverted model. Incidents at Google Scale. Steve McGhee @ LFI Conf 2023. youtube ![]()
YOUTUBE Fi5WBYVSFcg
Incidents at Google Scale. Steve McGhee @ LFI Conf 2023. youtube ![]()
Steve’s talk also touches on a theme that came up several times at the conference: the multi-party dilemma—challenges of software systems that cross company boundaries. One of Google's customers had done almost everything right creating separate failure domains in their move to Google Cloud Platform. But their use of an authentication service in a manner unforeseen by GCP led to an outage that took down the customer's systems in both regions.
.
SRE in Enterprise. Steve McGhee and James Brookbank @ SRECon EMEA 2022. Review of Enterprise Roadmap to SRE. youtube ![]() pdf
pdf ![]()
YOUTUBE MzZLGWy9wWw
SRE in Enterprise. Steve McGhee and James Brookbank @ SRECon EMEA 2022. Review of Enterprise Roadmap to SRE. youtube ![]() pdf
pdf ![]()
An important factor in this transition was the deliberate choice not to scale the operational costs associated with this shift to horizontal. That is, when scaling horizontally, it didn’t make financial sense to staff an operational team that scales linearly with the number of machines under their control.
This technological and financial choice drove an organizational one—arguably this is what begat SRE. Google simply made this choice before most other companies did because it was a very early web-scale company.
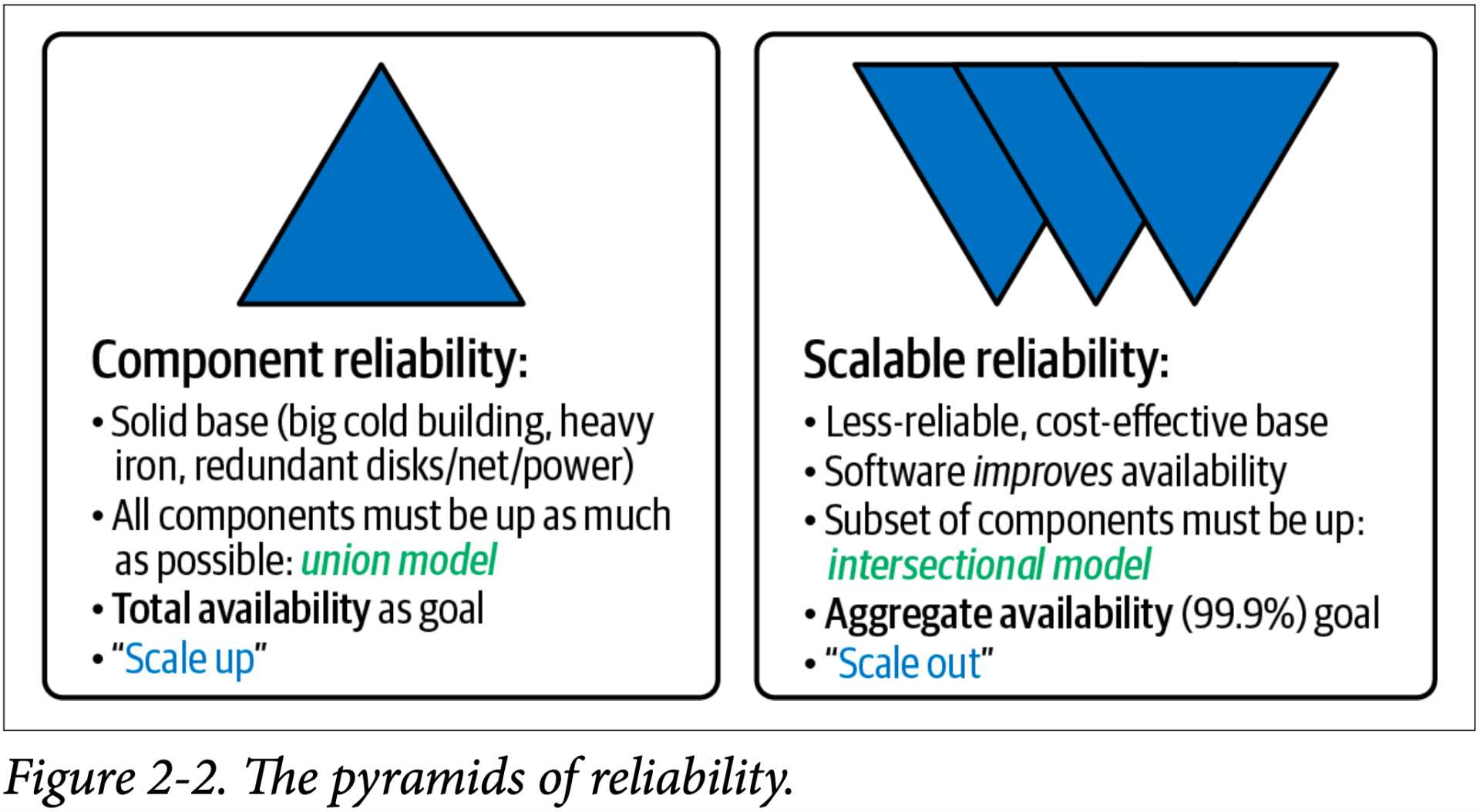
Traditional infrastructure follows the model of a building or a pyramid: a large strong base, built from the bottom up. If the base fails, this spells disaster for everything above it. We call this a component-based reliability model, or a union model, in which all components in a system are expected to be available for it to work. The newer model used in cloud computing (represented with three inverted pyramids) is that of a probabilistic-reliability or intersectional model, in which only a subset must be available for the system to work, due to architectural choices that expect failure.
.
Compare this article, also from Google. A service cannot be more available than the intersection of all its critical dependencies. Calculus of Service Availability. ACM Queue 2017. acm ![]()
If you have a critical dependency that does not offer enough 9s (a relatively common challenge!), you must employ mitigation to increase the effective availability of your dependency (e.g., via a capacity cache, failing open, graceful degradation in the face of errors, and so on.)
There are three main levers to make a service more reliable. * Reduce the frequency of outages—via rollout policy, testing, design reviews, etc. * Reduce the scope of the average outage—via sharding, geographic isolation, graceful degradation, or customer isolation. * Reduce the time to recover—via monitoring, one-button safe actions (for example, rollback or adding emergency capacity), operational readiness practice, etc. You can trade among these three levers to make implementation easier.
The paper goes on to include many excellent suggestions for engineering the relationship between a service and its critical dependencies.
.
Achieving DORA outcomes via Reliability Engineering in your Platform by Steve Mcghee. youtube ![]()